
Loading...


Let our Amazon experts show you how to leverage the power of ZonGuru to smash your sales goals. You’re invited to a 15-minute Rocket Demo so you can see the ZonGuru tools first-hand.
Book your seat now!
The shopper has already stopped scrolling. She wants chocolate protein powder, and before she buys she's got questions - ten of them, easily. How many calories per serving? Any artificial sweeteners? Does it taste chalky? Does it need refrigerating once it's open? A year ago she'd have dug through five listings to find out. Now she just asks Amazon's assistant, and the assistant answers from whichever listing actually bothered to say.
Take Huel's Black Edition Chocolate. On the page it looks great: 40 grams of protein, 27 vitamins, a confident Power your potential headline, clearly a listing the brand spent real money on. It looks finished, but it answers one of those ten questions outright. We know, because we scored it: 53 out of 100 on the AI Readiness Score - one number, 0 to 100, for how ready your listing is for the Amazon engines that now decide whether shoppers ever see it.

The 53 is a compound of two numbers, not one. On the COSMO Semantic substrate the Score reads Huel's listing at 68%; on the Alexa for Shopping Q&A substrate, it reads at 16% - and that 16 is the engine most listings were never built for. Where do Huel's two numbers come from, and why does the lower one matter more than the higher one?
The AI Readiness Score is the tool both numbers come from, and it gives you the picture in two minutes. You paste your ASIN, and the tool reads your listing against the COSMO graph and the question set Alexa for Shopping uses when a shopper asks. The score comes back as one number out of 100, free, with no payment, no credit card, and no signup. Details included.
Under that one combined number sit actually two - the Score reads your listing on two named substrates, and each comes back out of 100 alongside the combined figure. COSMO Semantic Mapping is the substrate that scores how well your listing fills the 15 named semantic relationships COSMO uses to interpret your product for the AI engine. Alexa for Shopping Q&A Coverage is the substrate that scores how well your listing answers the questions Alexa for Shopping draws from your copy when a shopper asks.
The Score is a diagnostic, not a verdict on your copy - it doesn't grade how well your listing reads to a human shopper, and it doesn't measure conversion or session count. Conversion still depends on the buyer's decision once they reach your page. The Score measures whether the two Amazon engines that decide if your listing reaches the buyer can read it at all.
The reads are evidence-extracted from your listing as Amazon shows it - title, bullets, description, A+ content, backend attributes you've made visible.
Two substrates because two engines now read the same listing. A9 still decides organic rank on the search results page, and a second engine now sits in front of it - and the substrate split inside your Score maps directly onto that engine split: COSMO Semantic Mapping reads what the AI engine sees, and Alexa for Shopping Q&A Coverage reads what the conversational layer can answer.
Alongside the two-substrate score, the same free run now reads your listing against Amazon's two hard character limits - it flags your title against the 75-character cap and your Item Highlights against the 125-character cap, then suggests a compliant version of each. The suggestion only reshapes the copy already in your listing to fit the limits, and whether to apply it stays your call. The score tells you which engines can parse your listing; the format check makes sure the listing clears the character ceilings those engines read it through in the first place.

A9 is the engine you've been writing for since you started selling on Amazon. It rewards keyword presence, keyword diversity, sales velocity, and conversion rate. On May 13, 2026, Amazon shipped a second engine and called it Alexa for Shopping: the engine that fuses what Rufus already did (read products and reason about them) with what Alexa+ already did (personalize over the About You profile Amazon now keeps on every shopper). Both engines read the same listing copy, and they reward different things.
COSMO is how the AI engine reads, and it works as a knowledge graph rather than a search algorithm - connecting products, queries, and intent across 6.3 million nodes and 29 million edges spanning 18 product categories, per Amazon's own Science paper. COSMO reads your listing in relationships, and the graph names fifteen of them: Function, Situation, Target Audience, Product Type, Capable Of, Solves Problem, Develops Skills, Compared To, Used In (Location), Used On (Time/Season), Used With (Complementary), and four more covering use-context, complementary-product, audience, and function dimensions. Each one is a question the engine asks: who is this product for, when do shoppers use it, what does it pair with, what does it sit beside in the buyer's decision. The full per-type breakdown lives separately; here, what matters is that COSMO Semantic Mapping scores how many of the fifteen your listing fills, and how deeply.
Huel's Black Edition Chocolate lands at 68% on the COSMO side because the listing develops six relationship types well: Function is clear (a meal-replacement protein powder), Situation is named (post-workout, busy mornings, between meetings), Target Audience is implied (active adults, fitness-aware buyers), Product Type is explicit, Capable Of is quantified (40g protein, 27 vitamins), and Solves Problem is clear (a complete meal in two minutes). The other nine sit underdeveloped or blank - Compared To carries no comparison to competing protein powders, Used In (Location) carries no kitchen-or-gym usage, Used On (Time/Season) carries no time-of-day or weekly cadence. The graph reads what's there; it can't fill what isn't.

Alexa for Shopping reads differently. When a shopper asks, the conversational agent doesn't search; it answers. To answer, it pulls from a category-specific question set the system generates per product type. For chocolate protein powder, the question set Alexa for Shopping draws from includes calories per serving, sugar content, sweetener type, scoop size, refrigeration, taste profile, ingredient sources, bloating, daily long-term safety, and mix-quality. The substrate scores how many of those questions your listing answers - outright, partially, or not at all.

Huel's Q&A score is 16%. The listing answers one of fourteen critical questions outright - the title says "17 Servings", which answers how long does one bag last? Three more are partial: will it keep me full for several hours?, does it mix well without a blender?, and is it safe for daily long-term use? Ten questions go unanswered: how many calories per serving, does it taste chalky, how much sugar per serving, what carbs per serving, does it contain artificial sweeteners, how many scoops per serving, does it cause bloating, what protein sources does it use, does it need refrigeration after opening, and is the chocolate flavor strong or subtle. Each missing answer is a question a shopper actually asked the buyer's research process. The conversational engine answers from whichever listing in the result set has the answer, and Huel's listing has, for ten of these, nothing.
Both engines read the same listing copy. The COSMO side reads what your listing develops as relationships; the Q&A side scores what it answers as questions. The lower side names which engine your listing was written for less, and 68/16 is what the keyword era looks like when scored against both.

Huel's 68/16 isn't an outlier. The median AI Readiness Score across more than 5,000 live Amazon listings is 65 out of 100. The number reads like a passing grade; the score functions as a structural ceiling. The 65 marks where a listing tops out after every keyword-era tactic, with no work yet for the new AI layer. Reading the 65 as "passing" misreads what the diagnostic measures - a band on a distribution, not a verdict on a listing.
The Score sorts results into three named bands - Strong (80–100), Adequate (50–79), Needs Work (below 50) - that name where on the curve your listing sits, not whether it's good or bad in isolation. The Strong band requires both substrates above 80. The Adequate band, where most of the catalog lives, clears the floor on at least one engine and carries meaningful coverage on the other. Needs Work means at least one substrate the engine can barely read.
Under the 65 sits an asymmetry. The COSMO Semantic median lands at 70; the Alexa for Shopping Q&A median lands at 54. Same listings, same 5,000+ runs, same place. The Adequate band's lower edge sits at 50, where the Q&A side often clusters; the band's higher edge sits at 79, where the COSMO side tops out. The 65 the Score returns combines both, and combining them hides the 16-point gap the diagnostic actually reveals.
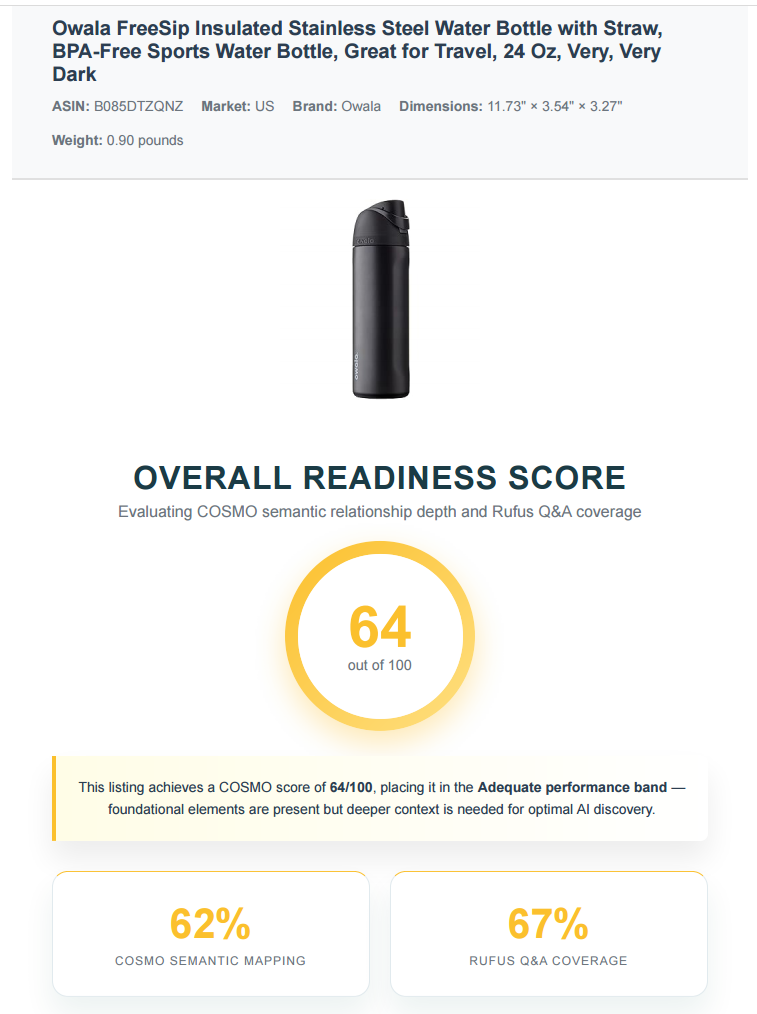
Owala's FreeSip Insulated Water Bottle in Very, Very Dark sits at 64 out of 100, barely Adequate. The substrate split reads as near-parity: COSMO at 62, Q&A at 67. The listing is strong on Function (24-hour cold retention is quantified verbatim) and on Capable Of (the FreeSip dual-mode spout is named, the cup-holder-friendly base is explicit). Q&A coverage answers 5 of 15 questions outright (cup-holder fit, dishwasher safety, 24-hour cold, hot liquid safety, ice cube addition), 7 are partial, and 3 go dead silent - are replacement straws available, how easy is it to clean the straw, and does the carry loop feel sturdy for daily use. Owala sits inside Adequate because both engines can read enough of the listing to position it. The coverage is uneven, but the engines aren't blind.
Adequate is where most listings live, and the band is the largest one on the curve. Reading Adequate as "good enough" is the costly misread. The 65 is the structural ceiling A9-tuned listings hit when they get scored on both layers, and pushing into Strong means doing work the keyword era never asked for. The band tells you where you sit on the curve; the substrate split tells you which engine you have to write for.
The split reads differently from listing to listing. Owala's near-parity is one shape; Huel's extreme inversion is another; two substrates similarly weak is a third. What the diagnostic does with each shape is name the engine the listing was written against.
Three shapes show up in the data: Owala's near-parity (62 / 67), Huel's extreme inversion (68 / 16), and a third shape where both substrates land similarly weak. The shape your listing's split takes is what the diagnostic uses to name which engine had less of your attention. Each shape predicts a different engineering entry point, and the entry point matters more than the headline number.
Start with Huel. The Black Edition Chocolate listing scored 53 out of 100, with COSMO at 68 and Q&A at 16. The 52-point gap is the catastrophe shape - fluent on the semantic engine, near-silent on the conversational one. The listing develops six of the fifteen COSMO relationships well, and that's where its lift is coming from today. But ten of fourteen category-generated questions go unanswered: the assistant has barely a signal to draw from when a shopper asks about calories, sugar, sweeteners, scoops, refrigeration. The diagnostic reading: Huel was written for the search results page where the protein-and-vitamins payload converts. The conversational engine wasn't a constraint when the copy was written, and the listing reflects that absence.
Owala's FreeSip - Very, Very Dark colorway - scored 64 out of 100, with COSMO at 62 and Q&A at 67. The 5-point gap reads as near-parity, with both substrates landing inside the same band and both engines having enough signal to position the listing. The Q&A side is, unusually, the slightly stronger one, because the bottle's category generates fairly literal questions (does it fit a cup holder, is it dishwasher safe, does it keep ice) and the listing answers those, because the brand has been writing to a product-comparison-aware buyer for years. The diagnostic reading: Owala's gap is coverage, not asymmetric blindness. Filling Target Audience and Used On (Time/Season) on the COSMO side and answering the three dead-silent Q&A items would push the listing into Strong without restructuring the copy.
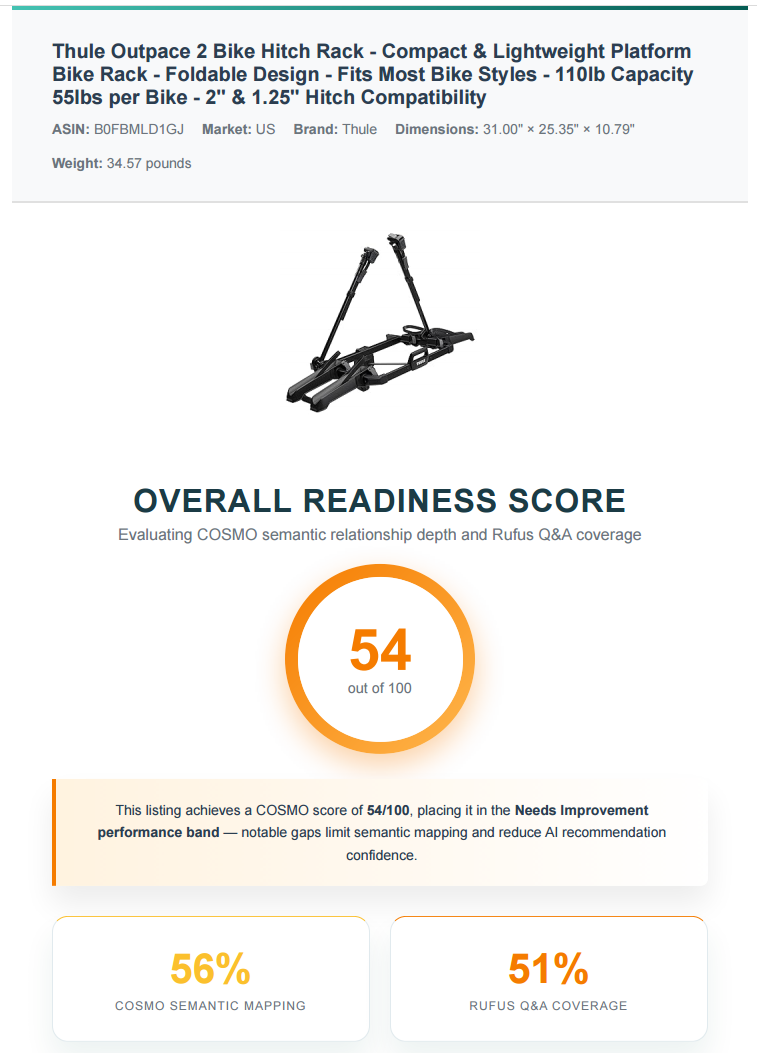
The flat-low shape sits at the third example. Thule's Outpace 2 Bike Hitch Rack scored 54 out of 100, with COSMO at 56 and Q&A at 51. Both substrates are weak, and the 5-point gap is flat-low rather than asymmetric. The listing names "110lb Capacity 55lbs per Bike" and quantifies tube diameters from 0.8 to 3.5 inches, strong on Product Type and Capable Of. But Target Audience is missing entirely (no cyclists, no families with multiple bikes, no weekend adventurers), and Compared To (Alternative) is missing too. On the Q&A side, the listing answers 6 of 15 questions outright (2" hitch fit, fat-tire compatibility, trunk access, electric bikes under 55lb, rack weight, foldability), 1 partial, and 8 unanswered - carbon-fiber frame compatibility, theft prevention, hitch-lock inclusion, assembly difficulty, one-person installation, license-plate clearance, folded dimensions for garage storage, and warranty terms. The diagnostic reading: Thule's listing was written for catalog management, not for either engine. Both substrates are undeserved.

The shape tells you what to fix first. Extreme inversion (Huel) means the conversational substrate is the binding constraint, and the unanswered-question set is where engineering starts. Near-parity (Owala) means coverage, not asymmetry - the move is filling the underdeveloped relationships and the dead-silent questions in parallel. Flat-low (Thule) means the listing has barely been written for either engine, and the move is to start from the audience, the comparison context, and the use cases the catalog data never carried.
The diagnostic is the easy part; the fix is the engineering. Before either, the diagnostic has to be in hand.
Score Your Listing - Free, in Under Two Minutes: Paste your ASIN. Get your COSMO Semantic Mapping number and your Alexa for Shopping Q&A Coverage number side by side, plus the per-relationship breakdown, the per-question gap list, and a 75/125 check that flags your title and Item Highlights against Amazon's character caps and suggests a compliant version of each. See Where Your Listing Stands. See Where Your Listing Stands →
A checklist won't read the asymmetry, and neither will a one-number audit. Why?
Four kinds of audit show up when you search for AI Readiness Score or Amazon listing audit - and each one returns a number without splitting the listing by which engine the gap lives on. That's the structural reason a checklist gives you a list of factors without telling you which factors are the ceiling.
Apify ships an Amazon Listing AI Score - Rufus Readiness Analyzer API through its marketplace. The artifact returns a number, and that's where the methodology ends. There is no published distribution behind it, no substrate split, no band taxonomy. You can hit the endpoint and get back a score, but you can't read what the score means against a benchmark, and you can't read which engine the gap lives on. The artifact arrived without the methodology that makes a score readable.
Adverio's frame splits Listing Quality Score (the human-readability layer) from Agent Add-to-Cart Readiness - AACR, a machine-readiness reading on a different taxonomy than COSMO's named relationships. Adverio's worked example reads as "the same product, two different failures" - a listing that scores well on LQS yet fails AACR. The framing is the closest the editorial set gets to the substrate split. But there is no public median benchmark and no public dimension breakdown for AACR, and the post ends on a call to book a 15-minute ROI Growth Forecast. The reading is gated behind sales.
Cosmy carries a CoSMo Content Score and a Rufus Visibility Score as product features (CoSMo is their spelling of COSMO). Both are gated behind a sales-led demo. There is no public benchmark distribution to read your number against, and no public methodology to read how the scoring works. The scoring exists, but the public reading does not.
The most common audit format on the market is the checklist. Cosmy's Complete Amazon Listing Audit Checklist (AI + Traditional) combines 25 traditional A9-hygiene elements with 35 AI factors, scored on a 0–60 scale across a four-week implementation plan. ShelfWise ships an instant six-category grader. Eva runs a paid listing optimizer audit. A checklist can flag sixty weak factors without telling you which sixty belong to the structural-ceiling layer and which belong to the keyword-era polish, and so the answer to what should I fix first? defaults to "the things you can fix easiest."
What the AI Readiness Score does is bring six properties into one diagnostic: free, 2-minute, ASIN-only, evidence-extracted, benchmarked against the 5,000+ run distribution, sub-scored per substrate, and banded Strong / Adequate / Needs Work. Apify's API returns the score without the distribution; Adverio's frame splits the layers but gates the reading behind a call; Cosmy's score is hidden behind a demo; the checklists flag sixty factors without naming which sixty are the ceiling. The asymmetry diagnostic - the reading that names which engine your listing was written for less - only works when the per-substrate split arrives inside a single result. The diagnostic is necessary but not yet sufficient; the fix is engineering against the lower substrate.
The pathway is short, and the order matters. Start with the substrate split your Score returns, and name which side is lower. On the median, the Q&A side is the lower one - across the 5,000+ runs published, the COSMO half clusters at 70 and the Q&A half at 54. On your listing, the diagnostic is read pairwise, and the substrate that scores lower names where the engineering starts.
The binding constraint is whichever side is lower. From there, the work splits into two queues. From the Q&A side, you pull the unanswered-question list - every gap on the substrate is a specific question the conversational engine could not answer for the shopper, named by the category's question set. From the COSMO side, you pull the underdeveloped relationships - every type at or below 50% coverage is a slot in the graph the engine can barely read.
Engineering against both happens at once, because answering a Q&A question well usually populates a COSMO relationship at the same time. A title that adds "24-hour cold retention for cyclists who lock the bike to a hitch rack at trailheads" gives the Q&A side a Target Audience answer, and gives COSMO four relationship signals in one phrase: Function, Used In (Location), Used With (Complementary), and Target Audience. The 15 relationship types are not a list you fill in order; they are a set you cover in tandem with the question set the conversational substrate generates.
Re-scoring is what makes the lift falsifiable. Run the listing through the Score again after the rewrite, and read the before/after substrate split. The Q&A side should move first, because answers stack against the question set directly. The COSMO side usually moves with it, because the same answers populate the relationships. If the lower side hasn't moved, the engineering didn't reach the gap, and the rewrite touched the easier work first.
Huel's listing shows what engineering against the lower substrate looks like in practice. The ten unanswered category-generated questions are: calories per serving, taste profile, sugar content, sweetener type, scoops per serving, refrigeration, bloating or digestive issues, protein sources, chocolate flavor strength, and artificial sweeteners. An engineered Huel listing names a calorie count in the bullets, says how the chocolate is sweetened (without forcing the shopper to scroll three nutrition images), and answers the scoop and refrigeration questions in the description. The COSMO side moves with those answers in tandem: Target Audience populates when the listing names busy parents, gym-goers, shift workers explicitly; Used In (Location) populates when the listing names kitchen, gym bag, office drawer; Compared To populates when the listing says how it compares to whey-based competitors. The work reads as writing answers more than as writing copy.
The full discipline of writing answers like this is what we name Listing Engineering - the AI-discovery counterpart to keyword-era copywriting, where the listing is built as structured answers to the questions both engines ask, rather than as keyword-density copy with persuasive bullets bolted on. The engineered version of the sequence above, run through the full method, becomes Helix™ Listing Engineering, ZonGuru's framework that turns the diagnostic into an engineered listing. Helix is built around three stages (Ingest, Analyze, Structure), a three-discipline composition (creative director, brand strategist, Amazon seller), and a brand-validation loop the engineered listing has to clear before it ships. Engagement is pay-per-ASIN: $49 single, from $44 per ASIN at catalog volume, from $30 per ASIN at portfolio scale (100+ credits).
The pathway works on one listing. Whether Huel's gap is an outlier or whether the asymmetry sits on the whole category is what the score distribution settles.
Across more than 5,000 scored listings, the COSMO half clusters at 70 and the Q&A half clusters at 54. These are the same listings showing the same gap in the same place. The asymmetry isn't random; it traces to a structural reason the category hasn't caught up to.
A9 rewards keyword density and keyword diversity. The Q&A substrate rewards specificity per category-generated question. A listing tuned for A9 covers the words a shopper might type, polished into bullets that read well. On the Q&A substrate, what counts is the questions the shopper actually asks - and the question set is generated by Amazon's category models, not by the listing's own copy. Keyword coverage and question coverage are not the same skill. The first compounds with copywriting hygiene, conversion testing, and pattern-matching to top performers. The second compounds with knowing exactly what the buyer asks before they buy, and writing the listing as the answer set rather than as the sales pitch.
The May 13, 2026 launch put Alexa for Shopping in front of more than 300 million Amazon shoppers - the same shoppers buying from your category, asking the assistant questions your listing has to answer. The post-launch adaptation window for sellers to bring listings into substrate compliance runs roughly 60 to 90 days, and the 5,000+ score distribution is the in-progress reading of that window. Most of the catalog hasn't adapted at scale. The 65 median is what that looks like as a single number, and the 54 Q&A median is what that looks like at the substrate that needs the most catch-up.
As listings move, the distribution moves. The discipline is to re-read the Score.
Re-score after every engineered rewrite. The before/after split tells you whether the rewrite moved the substrate that was lower, or whether it moved the substrate that was already higher - and the second outcome means the engineering didn't reach the gap. Re-score when Amazon's category-question set updates or when COSMO's relationship taxonomy shifts; both happen at irregular intervals tied to Amazon Science releases. Re-score once a new competitor enters your niche. It’s free.
Quarterly re-score the catalog is the baseline cadence for a brand running engineering at scale. Manual catalog audits break down past 50 ASINs, which is what tools like Helium 10's Listing Builder address at the keyword layer and what Helix addresses at the engineering layer. The economics of catalog-wide scoring sit in the volume tiers: $49 single, $44 per ASIN at catalog volume, $30 per ASIN at portfolio scale from 100+ credits. The diagnostic and the engineering travel together at scale.
Yes. We analyze your public listing data only, charge you nothing, ask for no credit card, and never send spam. You paste the ASIN, the tool reads what Amazon already shows, and the report comes back in two minutes.
Yes. Alongside the two-substrate score, the tool flags your title against Amazon's 75-character cap and your Item Highlights against the 125-character cap, and suggests a compliant version of each - reshaping the copy already in your listing to fit the limits rather than inventing new claims, with the call to apply it left to you. It runs free on the same ASIN paste, and the character check sits beside the 0-100 score rather than inside it. What no tool can decide for you is which keywords are load-bearing enough to keep inside 75 characters, because none can see which phrases hold your rank from listing data alone.
The two substrates score independently. COSMO Semantic Mapping scores how many of the 15 named relationship types your listing fills, weighted by tier - the highest-tier relationships count for more than the lower-tier ones. Alexa for Shopping Q&A Coverage scores the listing against a category-generated buyer-question set, with each question marked answered, partial, or missing. The two numbers combine into a single 0–100 score, and the band taxonomy - Strong (80–100), Adequate (50–79), Needs Work (below 50) - gives you the comparison against the published 5,000+ distribution.
Different taxonomies, different benchmark, different gate. The AI Readiness Score reads on COSMO's 15 named semantic relationship types and on the Alexa for Shopping category-generated question set; AACR reads on a machine-readiness framework Adverio has not published as a public dimension breakdown. The AI Readiness Score publishes a 5,000+ run median (65 out of 100, with the 70/54 split underneath); Adverio publishes no median. The AI Readiness Score is free, ASIN-only, with no demo gate; AACR routes through a 15-minute ROI Growth Forecast call.
The Score itself runs per-ASIN today - paste one ASIN, get one Score. The engineering side scales at credit-pack pricing: $44 per ASIN at catalog volume, and from $30 per ASIN at portfolio scale (100+ credits). The re-score discipline applies the same way at catalog scale; the rhythm is to score the catalog, identify the lowest-substrate listings, engineer those first, then re-score to confirm the lift.
Pulled together, the diagnostic does three things at once. It names where the gap lives - by substrate, not as a single number. It places that gap on the asymmetric median (COSMO at 70, Alexa for Shopping Q&A at 54), where the keyword era topped out and an audit checklist can't read. And it points engineering at the lower substrate, to be re-read and re-run after every pass - a continuous discipline, not a one-time test.
The shopper standing in front of Huel's Black Edition Chocolate listing has at least ten questions. Today the listing answers one outright, partially answers three, and falls silent on ten. The 53 out of 100 is what that looks like in a number, and the 16 on the Q&A substrate is what the silence looks like at the engine level. A Helix-engineered version of the same listing answers the calories, the sweeteners, the scoops, the refrigeration, the bloating, the protein sources. The shopper finishes reading, knows what she's buying, and adds the bag. The COSMO side moves with the Q&A side because the answers populate the relationships at the same time. The Score moves from 53 to wherever the engineering takes it, and the substrate split moves with it.
Naming the gap is the easy part. The AI Readiness Score is two numbers, not one - and the lower number always lives on the engine your listing was never built for. The fix is engineering against that engine: answering the questions, filling the relationships, re-reading the split, doing it again. Run your listing through the Score, read your two numbers, and see where it stands.
See Where Your Listing Stands: Paste your ASIN. Get your COSMO Semantic Mapping number and your Alexa for Shopping Q&A Coverage number side by side, with the per-relationship breakdown, the per-question gap list, and a 75/125 check on your title and Item Highlights - compliant suggestion included - in under two minutes. Run Your AI Readiness Score - Free.
Discover opportunities. Maximize your sales. Grow your Amazon business!

Free score in 2 minutes. See how Amazon's AI reads your listing and what to fix.
 Run my Free Score
Run my Free Score
Get started with ZonGuru, access all the tools with a FREE trial.
.webp) Start FREE Trial
Start FREE Trial



